Projekt
-
Ziel
Die Zukunftsvision Industrie 4.0 erfordert hochgradig vernetzte und wandlungsfähige Produktionssysteme. Um einen durchgängigen Informationsfluss innerhalb der gesamten Automatisierungspyramide zu gewährleisten, müssen Maschinen herstellerunabhängig, flexibel und effizient mit darüber liegenden IT-Systemen integriert werden können. Bestehende Integrationslösungen erfordern momentan einen enormen manuellen Aufwand. Ziel dieses Projektes ist die Entwicklung einer intelligenten, selbstkonfigurierenden und herstellerübergreifenden Kopplungskomponente, um verschiedene Maschinen auf eine neuartige Weise mit Informations- und Steuerungssystemen zu koppeln.
-
Idee
Die Grundidee der Kopplungskomponente liegt in der automatisierten Wiederverwendung von Integrationswissen. Die Kopplungskomponente soll in einer Lernphase den Datenfluss analysieren und hinterlegte Daten-Muster finden, um somit mögliche Informationsmodelle und Abbildungsregeln zwischen Quell- und Zielmodell ableiten zu können. Diese Regeln können dann für konkrete Datentransformationen eingesetzt werden. Durch das Speichern der Abbildungsregeln in einem Repository stehen diese in nachfolgenden Anbindungsprojekten bzw. bei Veränderungen der Maschinenkonfigurationen erneut zur Verfügung und können automatisiert übernommen oder angepasst werden. Mit steigender Anzahl an Maschinenanbindungen wächst das Kopplungswissen.
-
Nutzen
Mithilfe der im Vorhaben zu entwickelnden Lösung können sowohl Maschinenhersteller als auch Anwendungssystemhersteller die Integrierbarkeit und Adaptierbarkeit von Maschinen erheblich verbessern. Die Projektergebnisse stellen für beide Industriepartner eine fortschrittliche technologische Lösung für die Bearbeitung wiederkehrender Maschinenanbindungen/Integrationsfragestellungen dar.
Lösung
-
Modellierung
Das Projekt stellt verschiedene Sprachen zur Verfügung, um die Integration zwischen verschiedenen Systemen auf einer abstrakten Ebene zu beschreiben. Die Sprachen ermöglichen die Beschreibung von Datenstrukturen und Prozessen sowie deren Abbildung. Die Sprache wurde als Domain-Specific Language in Xtext als Eclipse Editor implementiert.
-
Generatoren
Code-Generatoren lesen die erstellten Modelle ein und erzeugen ausführbaren Source Code für verschiedene Ausführungsumgebungen. Der Generator überbrückt somit die Lücke zwischen abstrahierten Modellen und konkreten ausführbaren Programm-Code. Im Projekt wurden verschiedene Generatoren implementiert. Beispielsweise gibt es einen Generator, der Source Code für Spring Integration erzeugt.
-
Repository
Zum Management von Modellen steht ein Repository zur Verfügung. Im Repository können Projekte mit Modellen und dazugehörigen Source Code verwaltet werden. Hierzu werden Modelle als Graphen mit Neo4J gespeichert und ausgewertet. Die entstandene Wissensbasis aus Modellen und Projekten kann durchsucht und in Teil-Modelle in anderen Projekten wiederverwendet werden.
-
Integration
Im Projekt können verschiedene Ausführungsumgebungen der erzeugten Integrationslösung eingesetzt werden. Aktuell existieren Code-Generatoren, die Transformationen-Code für verschiedene Integrationsplattform erzeugen. Aktuell kann die Integrationsplattform des Partners znt sowie die Open-Source-Lösung Spring Integration verwendet werden. Weitere Integrationsplattformen sind durch entsprechende Generatoren möglich. In Abhängigkeit der Integrationsplattformen können diverse Adapter für die Anbindung von Systemen verwendet werden. Focus im Projekt sind OPC, OPC-UA, SECS-GEM, JSON und relationale Datenbanken.
Domänenspezifische Sprachen
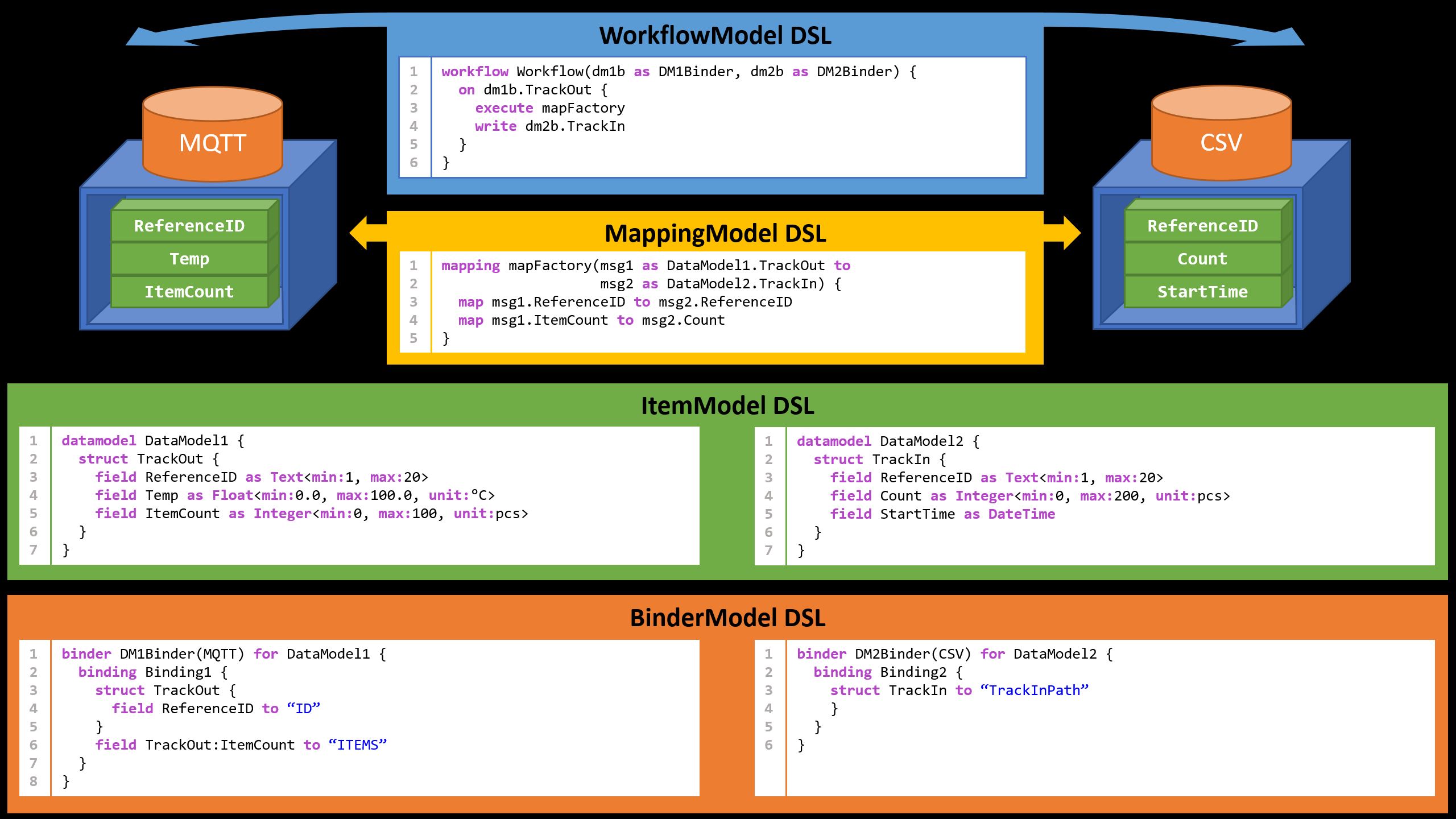
Item
Die Item DSL beschreibt die im Prozess verwendeten Daten-Entitäten. Diese werden typischerweise als Nachrichten oder Datensätze betrachtet, die eindeutig strukturierte und typisierte Informationsartefakte beinhalten. Die DSL bietet die Möglichkeit, innerhalb eines eigenen Namensraumes Strukturen anzulegen, die entweder aus Feldern vordefinierter Basistypen (z.B. Text, Float, Integer) oder selbst definierter komplexer Typen (auch Collections) bestehen. Basistypen bieten darüber hinaus die Möglichkeit von Beschränkungen (z.B. Text-Länge, physikalische Einheit, Wertebereiche).
Mapping
Die Mapping DSL bietet die Möglichkeit, existierende Daten-Entitäten feldweise aufeinander zu mappen. Dabei werden die verwendeten Datentypen und deren Beschränkungen automatisch validiert. Komplexe Mappingoperationen, die durch ein einfaches Zuweisen nicht möglich sind, können über Interfaces ausgeführt werden. Der Editor validiert das Vorhandensein geeigneter Interfaces und ermöglicht das automatische Erzeugen von Interface-Mappings. Während des Generationsprozesses wird direkt ausführbarer Code generiert. Die Implemetierung der Interfaces erfolgt manuell, zum Beispiel in Form von Bibliotheken.
Binder
Die Binder DSL beschreibt die Schnittstellen der angebundenen Systeme bzw. Adapter. Eine Reihe von Basisadaptern (z.B. CSV, XML) kann verwendet werden, um typische File-Datenformate zu unterstützen. Komplexere Bindermodelle sind geeignet, um Standard-Schnittstellen und/oder Protokolle wie MQTT, SECSII/GEM oder OPC-UA anzubinden.
Workflow
Die Workflow-DSL orchestriert die Integrationsabläufe. Hier kann zum Beispiel ereignisgetrieben das Mapping von Daten-Entitäten ausgelöst, sowie das Weitersenden zu anderen Adaptern modelliert werden. Voraussetzung ist eine vollständige Beschreibung von Daten-Entitäten mittels Item DSL, der Mapping-Beschreibungen mittels Mapping DSL, sowie der angebundenen System mittels Binder-DSL.
Partner
Ansprechpartner: Dr. Heiko Kern
Ansprechpartner: Holger Kremss
Ansprechpartner: Hans Mayer
Förderung
Das Projekt ist ein vom Bundesministerium für Bildung und Forschung (BMBF) gefördertes Forschungsvorhaben im Rahmen von KMU-innovativ. Die Projektlaufzeit ist vom 01.04.2017 bis 31.05.2019.
